6 minutes
Re-framing how we think about production incidents
I started a new gig 2.5 months ago and it’s been quite a fun journey in terms of how much I’ve had to learn. Starting a new job is not just about learning about technologies and processes, but also learning to adapt mental models you’ve previously built. It’s my second job and everything worked differently from my first one in terms of the engineering culture and processes. We believe in making small and iterative changes and deploying often to production as opposed to doing time bound releases. This has made me think a lot about blameless cultures and how folks early in their career can deal with breaking production (let’s just accept that it’s inevitable and will happen at some point or another and it’s okay)
The goal of this post is to provide some pointers about how teams can help new engineers deal with this and also folks early in their career can re-frame the way think about and deal with production outages.
Re-assurance from senior members of the team goes a long way
Fun fact: the first big change I worked on broke something in production 😂 I didn’t know what to do and how to deal with it so, me being me, I started panicking instantly. As soon as it was identified that it was my change that messed something up, my tech lead, Daniel Chatfield sent me a reassuring message. This very simple gesture on his part instantly calmed me down and meant a lot to me and is something that I’ll remember for a long time.
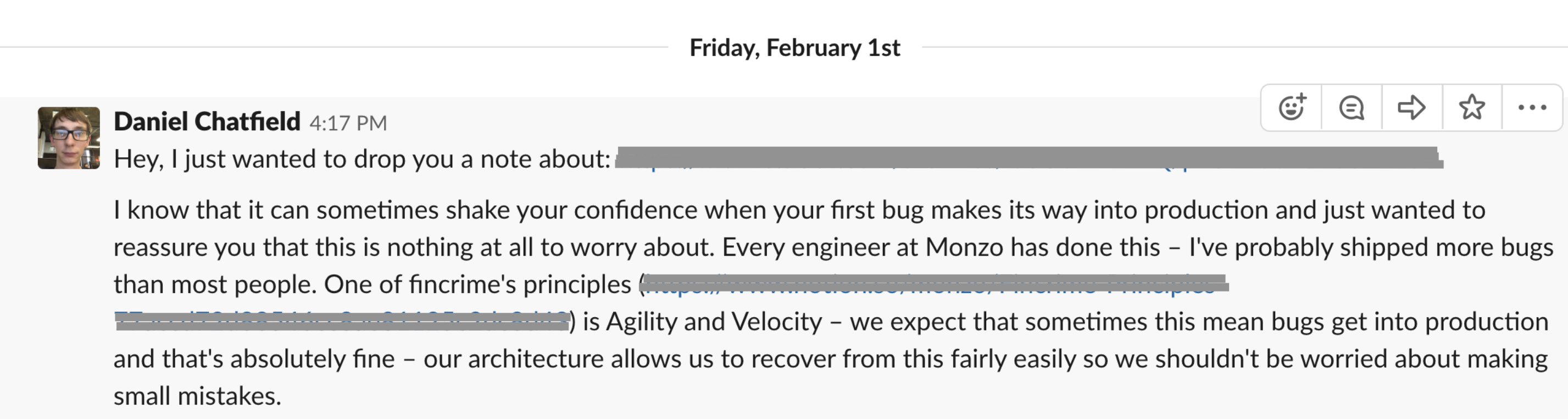
(Fincrime = Financial Crime, that’s the team I’m part of at Monzo)
Not all bugs are equal
At Monzo, we believe in deploying and shipping small, incremental changes regularly and our platform enables us to do exactly that. As a result, rolling back most changes in exceptionally easy — you just need to run a single command to revert the change.
However, not all bugs are equal. For example, in the particular case I outlined above, that wasn’t enough since some invalid data had been written to the database in the time before we detected the issue which needed to be fixed. Being new to the team, I was not super familiar with the service, but one of the more experienced members of the team with more context sat with me to explain how can go about fixing the invalid data calmly and I was able to write a fix confidently. 😊
It’s important to design systems and processes that make it difficult to ship large bugs to production. However, bugs will always slip through, and it’s invaluable to have tools that allow you to resolve issues quickly and limit the impact. In this case we used our iterator service (that allows us to run jobs across all of our users) to fix the invalid data quickly.
Talk about the stuff you fucked up
This can take the form of in-depth debriefs after an incident depending on how major it is, knowledge share sessions, detailed incident reports, etc. Detailed investigation reports can prove to be super useful here and they can be key in passing context which usually lives inside people’s heads to folks new to the team and can fill in gaps in documentation.
At Monzo, we recently started doing weekly lightning talks and one of the first ones was about “Stuff I broke in prod” by Matt Heath, one of our most senior engineers. It’s empowering to hear that literally everyone makes mistakes and it’s okay. Talking about things going wrong shouldn’t be something that fills you with shame or guilt. If that’s the case, it’s more likely to be an underlying cultural problem and not so much a technical one.
Communication is key
When you know you messed something up, the most important thing is to ask for help. At the end of the day, managing incidents is a team-sport and not a one-person-show. If there’s one thing you take away from this blog post, let it be this one. Don’t try to hide your mistakes in order to look smart. It’s not about you or your ego, it’s about fixing the mistake with the least amount of customer impact and you need all hands on deck for that as soon as possible. Communicating proactively is key here and it’ll make you a better and stronger team player in the long run.
Treat it as a learning opportunity
Even though this one feels like a no-brainer, I wanna give you some insight into how I like to think about it. When something breaks in production, I usually have mutliple takeaways from it:
- I learn to reason about our code better
- I learn how to debug the problem (or watch how other people reason about the problem which is also super fascinating for me because everyone’s brains work differently)
- People actually noticed when something breaks — this is a good thing! That means people use the stuff you build which is cool!
- It also gives the broader engineering team insight into how to make the processes more resilient to failures — fixing tooling, updating documentation, automating and detecting failure early, etc., so that the person who comes after you can avoid making the same mistake.
It’s never just one person’s fault
When something goes wrong, chances are even though you wrote the code, someone else reviewed it. And they didn’t catch the bug either. This isn’t an invitation to shift the blame on to them for whatever went wrong. It’s another way to look at the same thing: humans are flawed and will make mistakes no matter how perfect the tooling or automation. The goal isn’t to not make mistakes, it’s to learn from them and to avoid making the same mistake twice.
Engineering culture sets the tone for everything
How an individual reacts in such a situation is inherently tied to the team dynamics and the engineering culture of the organisation. If your workplace berates people for making mistakes and singles them out (believe me, this is more common than you think), then chances are very high that you will not feel comfortable talking to your colleagues or peers about your mistakes. This is an overarching point that is tangential to all of the other points I touched. Having a blameless culture where people feel safe to accept that they messed something underpins and is a hallmark of a good engineering team.
I would like to specifically highlight here that it can be really hard to folks in their first or second job to know what a good engineering culture looks like because they don’t have have the luxury to fallback on experience. It can leave folks completely disillusioned if their first job is a cultural dumpster fire and yet this isn’t uncommon at all. I’ve written more about toxic jobs and their symptoms in a different post. It is not your fault if you end up in a company with a terrible culture. 💖
To wrap up, I’ll try and summarise a conversation I had with a colleague about “humanising” bugs: instead of treating outages as an invitation to throw an individual under the bus, we should instead try and treat them as opportunity to make our systems better, more robust and more resilient to failure. 😊
Shoutout to Danielle Tomlinson, Daniel Chatfield and Suhail Patel for reviewing an early draft and providing useful feedback and everyone who chimed in with their suggestions in the Twitter thread on this topic! 😊