6 minutes
Retries in distributed systems: good and bad parts
Retries are a way to provide resiliency in a distributed system
When working with a distributed system, the only guarantee we have is that things will fail sooner or later. In these circumstances, we want to “design for failure”.
Retries are a technique that helps us deal with transient errors, i.e., errors that are temporary and are likely to disappear soon. Retries help us achieve resiliency by allowing the system to send a request repeatedly until it gets a success response. This is useful if you have some component in the path of the request failing the first time around.
There are two ways to retry a failed request:
- Manual retries: a failed request prompts the caller which in turn decides whether or not it wants to retry the request
- Automatic retries: a failed request is automatically retried by the system without any interference from the caller
For example, imagine a service A needs to talk to service B in order to finish the work it is supposed to do. What happens if service B fails when the request gets to it? We have two options here:
- return an error to A and do nothing
- return an error to A but automatically retry the request again
If we go down the second route, we can ensure that the system itself can take care of a failed request due to partial failure (C or D failing) without external intervention. This is a super useful feature to have in a distributed system where the probability of something failing at any given time is non-trivial.
Retries can lead to retry storms which can bring down the entire system
Retries, if employed without careful thought can be pretty devastating for a system as they can lead to retry storms. Let’s break down what happens during a retry storm with a real-world example.
Consider a queue for a customer service center. The representative can take one phone call every three minutes and the queue of callers keeps flowing smoothly. However, if a few customers are taking longer to be serviced, the rep is much slower than we’d expect them to be when taking calls.
Customers, on the other hand, aren’t prepared to wait more than a few minutes and will continue to ring the center from different numbers while being on hold in case the previous call gets through.. This overwhelms the phone line as they can’t figure out which call connections should be kept alive and which should be discarded.
A very similar situation can occur within a distributed system as well. Imagine, we’ve multiple services A, C, D and E all trying to talk to service B at the same time. C, D and E are unaware that A is trying to talk to B and vice-versa. If the request from any of A, C, D or E fails, we’ve the following scenarios:
- Best case: the retry succeeds in the first or second try
- Worst case: the requests can be stuck and will keep getting retried repeatedly if, for example, B is undergoing garbage collection
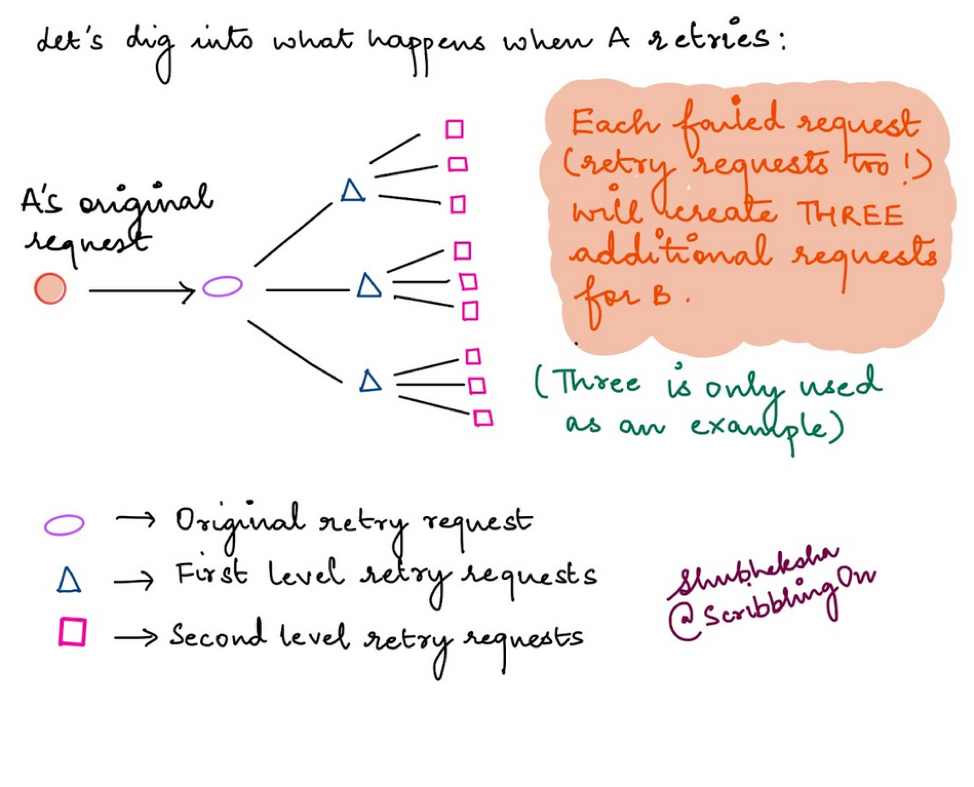
The worst case scenario can spiral out of hand really quickly if B is being issued lots of requests. All of them will fail and all of them will consequently be retried. It turns into a self-perpetuating cycle where every failed retry in-turn spawns X (X = number of retries your system is configured to use) retries.
We usually don’t retry retry requests (meta, I know) as this can lead to exponential growth and bring down a system really quickly. So only the initial failed request is re-tried within the system. Retry requests aren’t and shouldn’t be issued concurrently, they should be sequential instead in order to avoid increasing unnecessary load on the system.
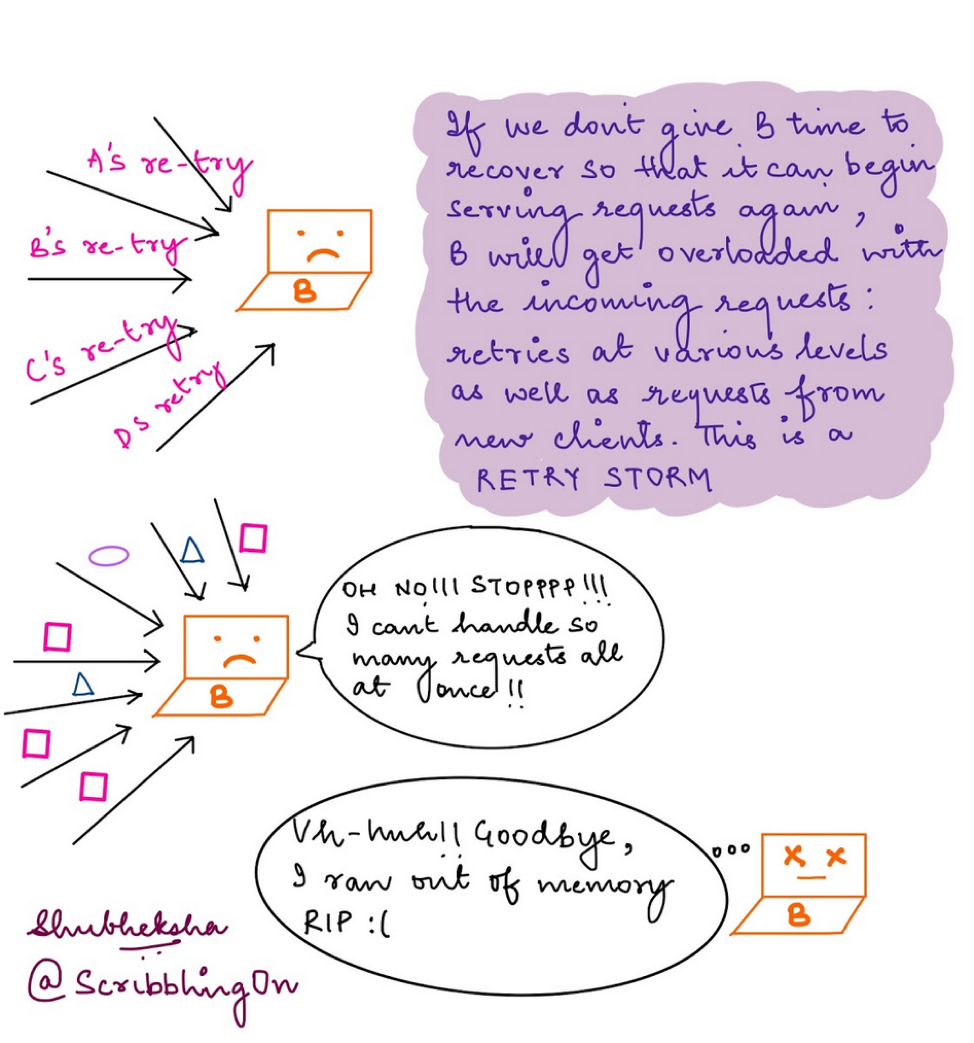
Let’s dig into what happens a little more to clarify it further. B is now being bombarded by different retry requests from multiple clients at the same time while continuing to receive normal traffic from various clients. The load grows linearly over time. This can quickly exhaust B as it will run out of compute and/or memory in order to cope with all the additional load.
Note: We use X=3 in the illustration, but the value of X will vary from system to system, it’s really hard to come up with a one-size-fits-all value for it. However, if you’re retrying requests in a loop, it’s a good idea to have an upper threshold for it which when reached should break out and terminate the request. This will avoid a scenario where we keep trying in an infinite loop.
This situation is known as a retry storm. If we have multiple of these across our system at the same time, then we can end up DDOSing our own system.
It’s not easy to detect a retry storm. Doing that will require every node to have a decent picture of what’s happening within the system.
Adding latency can work in our favour
As developers, we’re constantly taught that “fast is better”, so the idea of adding latency might seem a little weird at first. But it can be really helpful in distributed systems!
However, just adding the same amount of delay between two requests wouldn’t help. Let’s try to understand why. If, say, a hundred requests fail at the same time and we retry them all with a delay of 10ms, then we’re not solving the problem we had on our hands — we just shifted it 10ms into the future.
Exponential Backoff
Another option might be to delay each retry using an exponential delay: for simplicity, let’s use 2^n ms delay where n = retry count. Continuing from our previous example, we’ll see something like this:
- First retry: 2ms
- Second retry: 4ms
- Third retry: 8ms
It’s always a good idea to have an upper limit for backoff!
So and so forth. Again, this doesn’t solve our problem if multiple requests fail at the exact same time within our system (the chances of something like this happening in a real-world system are non-trivial). We’ll again issue the retry request at the same time and overwhelm the system. All we’ve done by this is added delay between successive re-tries without ensuring that they’re not synchronised across requests. However, it does give affected larger gaps of time to recover.
Jittering
To break this synchronisation, we can add randomness to the time interval by which we delay retries for a failed request. This is also known as “jittering” the request. In order to simplify understanding, let’s consider the following example:
- First retry: 2ms + 0.5 ms
- Second retry: 4ms + 0.8 ms
- Third retry: 8ms + 0.3 ms
By combining exponential backoff and jittering, we introduce enough randomness such that all requests are not retried at the same time. They can be more evenly distributed across time to avoid overwhelming the already exhausted node. This gives it the chance to complete a few in-flight requests without being bombarded by new requests simultaneously.
The illustrations used in this post are from a doodle I posted a couple of days ago:
New comic is all about retry storms! #devdoodles#sketchtogether pic.twitter.com/PcE9kJAbFk
— Shubheksha ✨ (@ScribblingOn) May 2, 2020
Lots of gratitude for Suhail and Ingrid for reviewing drafts of this post. 💜